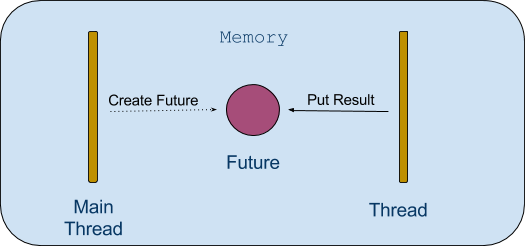
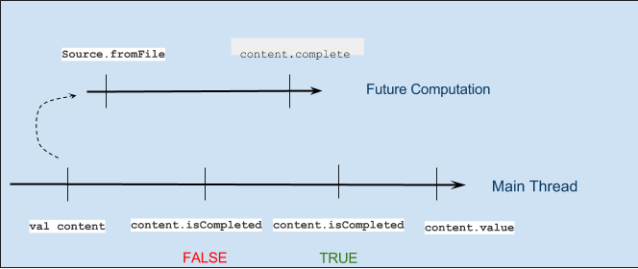
As we know, now days, most of the enterprise applications design as a "
Microservices Architecture" because of scalability, sharding, loosely-coupling and many others reasons are there. On the other hand
JavaEE help us for building an Enterprise Applications. As we know,
Java help us for building a good applications, but with
JavaEE monolithic approach our applications are not scalable as compare to microservices.
That's why,
Lagom comes into picture.
Lagom provides a way for building an
Enterprise Application with design of
Microservices based architecture and also give us
Responsive,
Resilient,
Elastic and
Message Driven features or in other words a
Reactive Approach.
Lagom design philosophy as :
- Asynchronous.
- Distributed Persistent.
- Developer Productivity.
In this blog, we are building a sample application, for managing user module and performing CRUD on user.
Note: Lagom gives us strict approach for designing applications with Domain Driven Design (DDD) manner and also follow CQRS for event sourcing.
Step-I:
We are building a maven based project using Lagom and our project structure is as below:
Step - II
As we know, Lagom follow DDD approach, so in maven based project we are creating submodules according to our domain. In, sample, we are managing user domain, so, we are creating two maven sub modules as "user-api" and "user-impl". user-api contains just specification and declarations of methods for our rest endpoints and in user-impl we actually implements, implementation of services.
In user-api, we are creating a class "UserService" and declare our all end points as below code:
public interface UserService extends Service {
ServiceCall> user(String id);
ServiceCall newUser();
ServiceCall updateUser();
ServiceCall delete(String id);
ServiceCall> currentState(String id);
@Override
default Descriptor descriptor() {
return named("user").withCalls(
restCall(GET, "/api/user/:id", this::user),
restCall(POST, "/api/user", this::newUser),
restCall(PUT, "/api/user", this::updateUser),
restCall(DELETE, "/api/user/:id", this::delete),
restCall(GET, "/api/user/current-state/:id", this::currentState)
).withAutoAcl(true);
}
}
Step III
Now in our user-impl module we are giving implementation of all services. For design a services, Lagom provide us strict model for following DDD. According to DDD we need Entities, Commands, Events and more. Initially we need to define commands for our module as below:
public interface UserCommand extends Jsonable {
@Value
@Builder
@JsonDeserialize
final class CreateUser implements UserCommand, PersistentEntity.ReplyType {
User user;
}
@Value
@Builder
@JsonDeserialize
final class UpdateUser implements UserCommand, PersistentEntity.ReplyType {
User user;
}
@Value
@Builder
@JsonDeserialize
final class DeleteUser implements UserCommand, PersistentEntity.ReplyType {
User user;
}
@Immutable
@JsonDeserialize
final class UserCurrentState implements UserCommand, PersistentEntity.ReplyType> {}
}
For designing a pojos in
Java, I am using
Lombok library for creating
immutables classes and remove boilerplate code.
Lagom also provide us
other options as well mention in documentations.
Note: You can use any library, but before using, configure your IDE according to library.
Step IV
We are following CQRS, so we need to define events as well:
public interface UserEvent extends Jsonable, AggregateEvent {
@Override
default AggregateEventTagger aggregateTag() {
return UserEventTag.INSTANCE;
}
@ValueEvent
@Builder
@JsonDeserialize
final class UserCreated implements UserEvent, CompressedJsonable {
User user;
String entityId;
}
@Value
@Builder
@JsonDeserialize
final class UserUpdated implements UserEvent, CompressedJsonable {
User user;
String entityId;
}
@Value
@Builder
@JsonDeserialize
final class UserDeleted implements UserEvent, CompressedJsonable {
User user;
String entityId;
}
}
Our events must be in compress form, because we need to persist hole event in db.
For more details go through lagom documentation.
Step V
We need to define our entity, and define behaviors according to commands and events as below:
public class UserEntity extends PersistentEntity {
@Override
public Behavior initialBehavior(Optional snapshotState) {
// initial behaviour of user
BehaviorBuilder behaviorBuilder = newBehaviorBuilder(
UserState.builder().user(Optional.empty())
.timestamp(LocalDateTime.now().toString()).build()
);
behaviorBuilder.setCommandHandler(CreateUser.class, (cmd, ctx) ->
ctx.thenPersist(UserCreated.builder().user(cmd.getUser())
.entityId(entityId()).build(), evt -> ctx.reply(Done.getInstance()))
);
behaviorBuilder.setEventHandler(UserCreated.class, evt ->
UserState.builder().user(Optional.of(evt.getUser()))
.timestamp(LocalDateTime.now().toString()).build()
);
behaviorBuilder.setCommandHandler(UpdateUser.class, (cmd, ctx) ->
ctx.thenPersist(UserUpdated.builder().user(cmd.getUser()).entityId(entityId()).build()
, evt -> ctx.reply(Done.getInstance()))
);
behaviorBuilder.setEventHandler(UserUpdated.class, evt ->
UserState.builder().user(Optional.of(evt.getUser()))
.timestamp(LocalDateTime.now().toString()).build()
);
behaviorBuilder.setCommandHandler(DeleteUser.class, (cmd, ctx) ->
ctx.thenPersist(UserDeleted.builder().user(cmd.getUser()).entityId(entityId()).build(),
evt -> ctx.reply(cmd.getUser()))
);
behaviorBuilder.setEventHandler(UserDeleted.class, evt ->
UserState.builder().user(Optional.empty())
.timestamp(LocalDateTime.now().toString()).build()
);
behaviorBuilder.setReadOnlyCommandHandler(UserCurrentState.class, (cmd, ctx) ->
ctx.reply(state().getUser())
);
return behaviorBuilder.build();
}
}
By default,
Lagom recommendations are using
Cassandra for events storing. But Lagom also support RDBMS as well.
For more details please click on this link.
Here we define our implementation of commands and events. In simple words, here we decide
what will happen with specific command and what will happen with specific event and maintain the state in memory.
Step VI
Sometimes, we also need to persist our data separately as well as events, in that case lagom provide us "ReadSideProcessor" abstract class perform operations according to events happened just like below:
public class UserEventProcessor extends ReadSideProcessor {
private static final Logger LOGGER = LoggerFactory.getLogger(UserEventProcessor.class);
private final CassandraSession session;
private final CassandraReadSide readSide;
private PreparedStatement writeUsers;
private PreparedStatement deleteUsers;
@Inject
public UserEventProcessor(final CassandraSession session, final CassandraReadSide readSide) {
this.session = session;
this.readSide = readSide;
}
@Override
public PSequence> aggregateTags() {
LOGGER.info(" aggregateTags method ... ");
return TreePVector.singleton(UserEventTag.INSTANCE);
}
@Override
public ReadSideHandler buildHandler() {
LOGGER.info(" buildHandler method ... ");
return readSide.builder("users_offset")
.setGlobalPrepare(this::createTable)
.setPrepare(evtTag -> prepareWriteUser()
.thenCombine(prepareDeleteUser(), (d1, d2) -> Done.getInstance())
)
.setEventHandler(UserCreated.class, this::processPostAdded)
.setEventHandler(UserUpdated.class, this::processPostUpdated)
.setEventHandler(UserDeleted.class, this::processPostDeleted)
.build();
}
// Execute only once while application is start
private CompletionStage createTable() {
return session.executeCreateTable(
"CREATE TABLE IF NOT EXISTS users ( " +
"id TEXT, name TEXT, age INT, PRIMARY KEY(id))"
);
}
/*
* START: Prepare statement for insert user values into users table.
* This is just creation of prepared statement, we will map this statement with our event
*/
private CompletionStage prepareWriteUser() {
return session.prepare(
"INSERT INTO users (id, name, age) VALUES (?, ?, ?)"
).thenApply(ps -> {
setWriteUsers(ps);
return Done.getInstance();
});
}
private void setWriteUsers(PreparedStatement statement) {
this.writeUsers = statement;
}
// Bind prepare statement while UserCreate event is executed
private CompletionStage> processPostAdded(UserCreated event) {
BoundStatement bindWriteUser = writeUsers.bind();
bindWriteUser.setString("id", event.getUser().getId());
bindWriteUser.setString("name", event.getUser().getName());
bindWriteUser.setInt("age", event.getUser().getAge());
return CassandraReadSide.completedStatements(Arrays.asList(bindWriteUser));
}
/* ******************* END ****************************/
/* START: Prepare statement for update the data in users table.
* This is just creation of prepared statement, we will map this statement with our event
*/
private CompletionStage> processPostUpdated(UserUpdated event) {
BoundStatement bindWriteUser = writeUsers.bind();
bindWriteUser.setString("id", event.getUser().getId());
bindWriteUser.setString("name", event.getUser().getName());
bindWriteUser.setInt("age", event.getUser().getAge());
return CassandraReadSide.completedStatements(Arrays.asList(bindWriteUser));
}
/* ******************* END ****************************/
/* START: Prepare statement for delete the the user from table.
* This is just creation of prepared statement, we will map this statement with our event
*/
private CompletionStage prepareDeleteUser() {
return session.prepare(
"DELETE FROM users WHERE id=?"
).thenApply(ps -> {
setDeleteUsers(ps);
return Done.getInstance();
});
}
private void setDeleteUsers(PreparedStatement deleteUsers) {
this.deleteUsers = deleteUsers;
}
private CompletionStage> processPostDeleted(UserDeleted event) {
BoundStatement bindWriteUser = deleteUsers.bind();
bindWriteUser.setString("id", event.getUser().getId());
return CassandraReadSide.completedStatements(Arrays.asList(bindWriteUser));
}
/* ******************* END ****************************/
}
Fore more details, please click on link.
Step VII
Finally we are going to define implementation of our rest service endpoints as below:
public class UserServiceImpl implements UserService {
private final PersistentEntityRegistry persistentEntityRegistry;
private final CassandraSession session;
@Inject
public UserServiceImpl(final PersistentEntityRegistry registry, ReadSide readSide, CassandraSession session) {
this.persistentEntityRegistry = registry;
this.session = session;
persistentEntityRegistry.register(UserEntity.class);
readSide.register(UserEventProcessor.class);
}
@Override
public ServiceCall> user(String id) {
return request -> {
CompletionStage> userFuture =
session.selectAll("SELECT * FROM users WHERE id = ?", id)
.thenApply(rows ->
rows.stream()
.map(row -> User.builder().id(row.getString("id"))
.name(row.getString("name")).age(row.getInt("age"))
.build()
)
.findFirst()
);
return userFuture;
};
}
@Override
public ServiceCall newUser() {
return user -> {
PersistentEntityRef ref = userEntityRef(user);
return ref.ask(CreateUser.builder().user(user).build());
};
}
@Override
public ServiceCall updateUser() {
return user -> {
PersistentEntityRef ref = userEntityRef(user);
return ref.ask(UpdateUser.builder().user(user).build());
};
}
@Override
public ServiceCall delete(String id) {
return request -> {
User user = User.builder().id(id).build();
PersistentEntityRef ref = userEntityRef(user);
return ref.ask(DeleteUser.builder().user(user).build());
};
}
@Override
public ServiceCall> currentState(String id) {
return request -> {
User user = User.builder().id(id).build();
PersistentEntityRef ref = userEntityRef(user);
return ref.ask(new UserCurrentState());
};
}
private PersistentEntityRef userEntityRef(User user) {
return persistentEntityRegistry.refFor(UserEntity.class, user.getId());
}
}
There are still lots of things
Lagom provide us, for developing enterprise applications. Which we will cover in our next blog.
Full source of this example, please click on link.