This is my first video tutorials on Akka Remoting. There are multiples combinations for creating Akka Remote actor and communicate with them. In this tutorials, we are discussing 5 ways for communicate with remote actors. The source code for this examples are available https://github.com/harmeetsingh0013/learning-akka-cluster git hub repo. Please send feedback on comments. I hope you guys learning new from this video.
Showing posts with label concurrency. Show all posts
Showing posts with label concurrency. Show all posts
Thursday, March 23, 2017
Saturday, February 25, 2017
Apache Kafka: Multiple ways for Consume or Read messages from Kafka Topic
In our previous post, we are using Apache Avro for producing messages to the kafka queue or send message to the queue. In this post, we are going to create Kafka consumers for consuming the messages from Kafka queue with avro format. Like in previous post, there are multiple ways for producing the messages, same as with consumer, there are multiple ways for consuming messages from kafka topics.
As per previous post, with avro, we are using confluent registry for managing message schema. Before deserializing message kafka consumer read the schema from registry server and deserialize schema with type safety. If we want to check our schema is schema server, we can hit following end point using any rest tool.
As per previous post, with avro, we are using confluent registry for managing message schema. Before deserializing message kafka consumer read the schema from registry server and deserialize schema with type safety. If we want to check our schema is schema server, we can hit following end point using any rest tool.
- http://localhost:8081/subjects (List of all save schema)
- http://localhost:8081/subjects/<schema-name>/versions/1 (For detail structure of schema)
I: Simple Consumer
Like simple producer, we have simple Consumer for consuming messages produced by simple consumer. The best practices are, we need to follow same way for Producing/Consuming messages from topic.
public class SimpleConsumer {
private static Properties kafkaProps = new Properties();
static {
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG, "CustomerCountryGroup");
}
private static void infinitePollLoop() {
try(KafkaConsumer kafkaConsumer = new KafkaConsumer<>(kafkaProps)){
kafkaConsumer.subscribe(Arrays.asList("CustomerCountry"));
while(true) {
ConsumerRecords records = kafkaConsumer.poll(100);
records.forEach(record -> {
System.out.printf("Topic: %s, Partition: %s, Offset: %s, Key: %s, Value: %s",
record.topic(), record.partition(), record.offset(),
record.key(), record.value()); System.out.println(); }); } } } public static void main(String[] args) { infinitePollLoop(); } }
II: Apache Avro DeSerialization Generic Format:
Like Generic format producer, we have same Generic format consumer as well. In consumer, the same thing we need like avro schema or generated POJO class, by any built tools generator or plugin.
public class AvroGenericConsumer {
private static Properties kafkaProps = new Properties();
static {
// As per my findings 'latest', 'earliest' and 'none' values are used with
kafka consumer poll.
kafkaProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG, "AvroGenericConsumer-GroupOne");
kafkaProps.put("schema.registry.url", "http://localhost:8081");
kafkaProps.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
}
public static void infiniteConsumer() throws IOException {
try (KafkaConsumer kafkaConsumer = new KafkaConsumer<>(kafkaProps)) {
kafkaConsumer.subscribe(Arrays.asList("AvroGenericProducerTopics"));
while (true) {
ConsumerRecords records = kafkaConsumer.poll(100);
records.forEach(record -> {
CustomerGeneric customer = (CustomerGeneric) SpecificData.get()
.deepCopy(CustomerGeneric.SCHEMA$, record.value()); System.out.println("Key : " + record.key()); System.out.println("Value: " + customer); }); } } } public static void main(String[] args) throws IOException { infiniteConsumer(); } }
III: Apache Avro DeSerialization Specific Format One:
This example is used for deserializer kafka message with specific format. This deserializer is used with corresponding Apache Avro Serialization Specific Format One in our previous post. In this we are using Kafka Stream from deserialize the message. There is another simple way for deserialize the message which we will look into next example.
public class AvroSpecificProducerOne {
private static Properties kafkaProps = new Properties();
private static KafkaProducer kafkaProducer;
static {
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
kafkaProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
kafkaProps.put("schema.registry.url", "http://localhost:8081");
kafkaProducer = new KafkaProducer<>(kafkaProps);
}
public static void fireAndForget(ProducerRecord record) {
kafkaProducer.send(record);
}
public static void asyncSend(ProducerRecord record) {
kafkaProducer.send(record, (recordMetaData, ex) -> {
System.out.println("Offset: " + recordMetaData.offset());
System.out.println("Topic: " + recordMetaData.topic());
System.out.println("Partition: " + recordMetaData.partition());
System.out.println("Timestamp: " + recordMetaData.timestamp());
});
}
public static void main(String[] args) throws InterruptedException, IOException {
Customer customer1 = new Customer(1001, "Jimmy");
Customer customer2 = new Customer(1002, "James");
ProducerRecord record1 = new ProducerRecord<>("AvroSpecificProducerOneTopic",
"KeyOne", customer1
);
ProducerRecord record2 = new ProducerRecord<>("AvroSpecificProducerOneTopic",
"KeyOne", customer2
);
asyncSend(record1);
asyncSend(record2);
Thread.sleep(1000);
}
}
IV: Apache Avro DeSerialization Specific Format Two:
This example of deserializer is used to deserialize message from kafka queue by Apache Avro Serialization Specific Format One producer. In the previous example we are using Kafka Streams, But in this, we are using simple way for deserialize the message.
public class AvroSpecificDeserializerThree {
private static Properties kafkaProps = new Properties();
static {
// As per my findings 'latest', 'earliest' and 'none' values are used with kafka consumer poll.
kafkaProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG, "AvroSpecificDeserializerThree-GroupOne");
kafkaProps.put("schema.registry.url", "http://localhost:8081");
kafkaProps.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
}
public static void infiniteConsumer() throws IOException {
try (KafkaConsumer kafkaConsumer = new KafkaConsumer<>(kafkaProps)) {
kafkaConsumer.subscribe(Arrays.asList("AvroSpecificProducerOneTopic"));
while (true) {
ConsumerRecords records = kafkaConsumer.poll(100);
records.forEach(record -> {
Customer customer = record.value();
System.out.println("Key : " + record.key());
System.out.println("Value: " + customer);
});
}
}
}
public static void main(String[] args) throws IOException {
infiniteConsumer();
}
}
V: Apache Avro DeSerialization Specific Format Three:
In this example we deserialize our messages from kafka with some Specific format. This is used for Apache Avro Serialization Specific Format Two producer in our previous post.
public class AvroSpecificDeserializerTwo {
private static Properties kafkaProps = new Properties();
static {
// As per my findings 'latest', 'earliest' and 'none' values are used with kafka consumer poll.
kafkaProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG, "AvroSpecificDeserializerTwo-GroupOne");
kafkaProps.put("schema.registry.url", "http://localhost:8081");
kafkaProps.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
}
public static void infiniteConsumer() throws IOException {
try (KafkaConsumer kafkaConsumer = new KafkaConsumer<>(kafkaProps)) {
kafkaConsumer.subscribe(Arrays.asList("AvroSpecificProducerTwoTopic"));
while (true) {
ConsumerRecords records = kafkaConsumer.poll(100);
records.forEach(record -> {
DatumReader customerDatumReader = new SpecificDatumReader<>(Customer.SCHEMA$);
BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(record.value(), null);
try {
Customer customer = (Customer) customerDatumReader.read(null, binaryDecoder);
System.out.println("Key : " + record.key());
System.out.println("Value: " + customer);
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
}
public static void main(String[] args) throws IOException {
infiniteConsumer();
}
}
Still there are lots of ways for Produce/Consume messages from kafka. Some of the way we are discuss here, for other, may be we will come with new posts. Please feel free for sending feedback and post the comments.
References:
Thursday, September 22, 2016
Scala Future Under The Hood
In the previous post , i was discussing about Scala ExecutionContext. As we know, for multithreading we need to maintain thread pools using ExecutionContext and by default ForkJoinPool is used because for accessing “multi core” processor. There are multiple thread pools are available in our java.util.concurrent.Executors utility class and as per our requirement we can create new one also.
After all, Scala have concept of Future. Why? In multithreading programming, large or heavy processes were executed on background or in new threads, but the most common problem we are facing is to handle return values from separate thread or handle exceptions or errors. This is the reason, some time developers starts heavy process in synchronized way because we need to access the values after computation and handle exceptions or more.
Note: Scala Future is the rich concept for handling multiple thread and there values after computations or handling error or exceptions if something happen in separate thread.
In scala api’s, Future is a trait and Future also has its companion object which has following apply method.
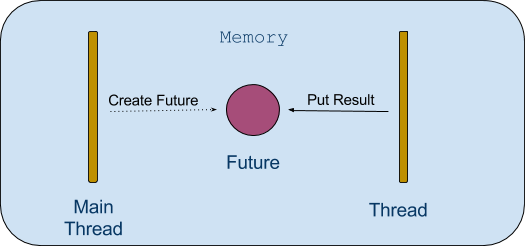
In simple words, Future is a placeholder, that is, a memory location for the value. This placeholder does not need to contain a value when the future is created. The value can be placed into the future eventually when the processing is done.
Let we assume, i have a method called renderPage and return content of web page as Future[String]:
This removes blocking from the renderPage method, but it is not clean how the calling thread can extract the content from Future ?
Polling is one of way , In which the calling thread calls a special method to block until the values becomes available. While this approach does not eliminate blocking, it transfer the responsibility of blocking from renderPage method to the caller thread (Main Thread).
Future Polling Example:
The conceptual diagram for our pooling mechanism as below:
Scala Futures have allow additional ways for handling future values and avoid blocking. For more information please click on link
References:
After all, Scala have concept of Future. Why? In multithreading programming, large or heavy processes were executed on background or in new threads, but the most common problem we are facing is to handle return values from separate thread or handle exceptions or errors. This is the reason, some time developers starts heavy process in synchronized way because we need to access the values after computation and handle exceptions or more.
Note: Scala Future is the rich concept for handling multiple thread and there values after computations or handling error or exceptions if something happen in separate thread.
In scala api’s, Future is a trait and Future also has its companion object which has following apply method.
def apply[T](body: => T) (implicit executor: ExecutionContext): Future[T]apply method accept future body as named parameter and ExecutionContext as implicit parameter because when future starts to process the body, it will execute the body in separate thread or (asynchronously) by using ExecutionContext.
In simple words, Future is a placeholder, that is, a memory location for the value. This placeholder does not need to contain a value when the future is created. The value can be placed into the future eventually when the processing is done.
Let we assume, i have a method called renderPage and return content of web page as Future[String]:
def renderPage(path: String): Future[String] = {
Future { ……………….. }
}
When the method calls, the Future singleton object followed by a block is a syntactic sugar for calling the Future.apply method. The Future.apply method acts similar as asynchronously. Its starts process in separate thread and render the content of webpage and place the webpage content into the Future when they become available. Following is the just a conceptual diagram for this example:This removes blocking from the renderPage method, but it is not clean how the calling thread can extract the content from Future ?
Polling is one of way , In which the calling thread calls a special method to block until the values becomes available. While this approach does not eliminate blocking, it transfer the responsibility of blocking from renderPage method to the caller thread (Main Thread).
Future Polling Example:
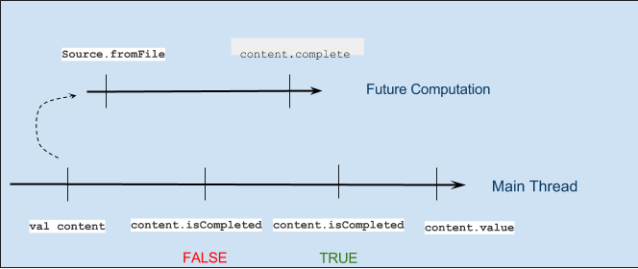
def futurePooling: Unit = {
val content = Future { scala.io.Source.fromFile("/home/harmeet/sample").mkString }
println("Start reading the file asynchronously")
println(s"Future status: ${content.isCompleted}")
Thread.sleep(250)
println(s"Future status: ${content.isCompleted}")
println(s"Future value: ${content.value}")
}
In example we are using method which are performing polling for us and after check its completion status, we are fetching the values using method.def isCompleted: Boolean def value: Option[Try[T]]Note: Polling is like calling your potentials employer every 5 minutes to ask if you’re hired
The conceptual diagram for our pooling mechanism as below:
Scala Futures have allow additional ways for handling future values and avoid blocking. For more information please click on link
References:
- Learning Concurrent Programming in Scala by Aleksandar Prokopec.
- Java api’s docs.
Java Executor Vs Scala ExecutionContext
Java supports low-level of concurrency and some of rich api’s which is just a wrapper of low-level constructs like wait, notify, synchronize etc, But with Java concurrent packages Scala have high level concurrency frameworks for “which goal to achieve, rather than how to achieve“. These types of programming paradigms are “Asynchronous programming using Futures“, “Reactive programming using event streams“, “Actor based programming” and more.
Note: Thread creation is much more expensive then allocating a single object, acquiring a monitor lock or updating an entry in a collection.
For high-performance multi-threading application we should use single thread for handling many requests and a set of such reusable threads usually called thread pool.

In java, Executor is a interface for encapsulate the decision of how to run concurrently executable work tasks, with an abstraction. In other words, this interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc
Java Executor :
Note: java.util.concurrent.Executors is a utility class, which is used to create create thread pool according to requirements.
References:
Note: Thread creation is much more expensive then allocating a single object, acquiring a monitor lock or updating an entry in a collection.
For high-performance multi-threading application we should use single thread for handling many requests and a set of such reusable threads usually called thread pool.
In java, Executor is a interface for encapsulate the decision of how to run concurrently executable work tasks, with an abstraction. In other words, this interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc
interface Executor{
public void execute(Runnable command)
}
Java Executor :
- Executor decide on which thread and when to call run method of Runnable object.
- Executor object can start a new thread specifically for this invocation of execute or even the execute the Runnable object directly on the caller thread.
- Tasks scheduling is depends on implementation of Executor.
- ExecutorService is a sub interface of Executor for manage termination and methods that can produce a future for tracking progress of one or more asynchronous tasks.
- In Java some basic Executor implementations are ThreadPoolExecutor (JDK 5), ForkJoinPoll (JDK 7) etc or developers should are provide custom implementation of Executor.

trait ExecutionContext {
def execute(runnable: Runnable): Unit
def reportFailure(cause: Throwable): Unit
}
Scala ExecutionContext:- ExecutionContext also have an companion object which have some methods for creating ExecutionContext object from Java Executor or ExecutorService (act as a bridge between Java and Scala)
- ExecutionContext companion object contains the default execution context called global which internally uses a ForkJoinPool instance.
Note: java.util.concurrent.Executors is a utility class, which is used to create create thread pool according to requirements.
References:
- Learning Concurrent Programming in Scala by Aleksandar Prokopec.
- Java api’s docs.
Subscribe to:
Posts (Atom)